
Like the article I came across recently, in which theoretical physicist Michio Kaku claimed that “time travel is now simply an engineering problem”, I sometimes find that developing applications in the world of Customer Identity is not dissimilar, particularly if you’re building a SPA.
“You’re vulnerable to XSS attacks if you keep tokens in Local Storage!”, “Prefer short-lived tokens”, “Use a BFF“, and “Follow the Principle of Least Privilege” are just some of the pieces of advice you’ll hear as a software engineer. I myself have said some very similar things in many of the articles I’ve written.
The challenge most software engineering folks have, though, is exactly how to do all that?!? SPAs are notoriously challenging when it comes to Customer Identity, particularly from a security perspective (as outlined in the IETF draft document here). And so, just like the mechanical, electrical and electronic engineers left to figure out how to make time travel a reality, the software engineers integrating with a CIAM solution are more often than not left to figure things out too!
My name’s Peter Fernandez, and in this article, I’m going to discuss one of the more challenging use cases: how to integrate Identity from an Access Management perspective into a Single Page Application in the most secure and user-friendly way possible. Hopefully providing some practical insight along the way as well 😎
What is a Single Page Application?
Fueled by frameworks like React, Vue, Angular, etc., the Single Page Application paradigm (or SPA for short) has grown in prominence over the years, providing a means for building web applications that interact with the user by dynamically updating the current web page with new data instead of loading entirely new pages. This results in a predominantly faster, more app-like overall experience for the user, as page reload isn’t required for each user interaction.
From a developer perspective, a SPA also offers significant cost savings, as it can be loaded from what is essentially a CDN and requires little to no persistent web server interaction.
To achieve its goals, a SPA will typically leverage one or more resource servers (APIs), which are server-side components implemented in a non-persistent fashion. Whilst calling an API will consume resources and will likely incur a cost where third-party hosting is concerned, once the API completes, no further resources are typically used (nor charges incurred). If you want to learn more, James Quick provides a contrasting comparison in his video entitled Multi page vs Single Page Applications – Which One Is Right For You?!
Whilst a discussion concerning SPAs vs Regular (Multi-page) Web Applications is beyond the scope of this article, it’s a reasonable argument to say that with Server Side Rendering (SSR), the line between Single Page Applications and Regular Web Applications — a.k.a. Multi Page Applications — blurs to some extent.
While the Single Page Application paradigm offers an attractive proposition to the application developer, they are particularly susceptible to certain security vulnerabilities, e.g. Cross-Site Scripting (XSS), as a prime example. In essence, if a SPA implementation isn’t using security-conscious practices, then, without the confidential-client aspect provided by a dedicated backend, a SPA is typically forced to rely on client-side storage mechanisms that are inherently insecure.
Challenges Integrating a CIAM Solution
From a Customer Identity perspective, integration as part of a SPA is a challenge. Particularly when it comes to API usage. As discussed, the best-practice advice you’ll typically encounter advises against the use of anything that can facilitate the likes of XSS attacks, including the avoidance of insecure storage mechanisms, together with anything that gives a would-be attacker something that they can ultimately wreak havoc with.
XSS — short for Cross Site Scripting — is a threat that has been around almost as long as the web itself! It’s beyond the scope of this article to explain in detail, but Jeff Crume, an IBM Distinguished Engineer, does a good job in his video entitled “Cross-Site Scripting: A 25-Year Threat That Is Still Going Strong“, and I’d recommend checking it out to learn more.
Token Safety
When it comes to an XSS attack, the ability to steal tokens — as in the ID Token and, more importantly, the Access Token and/or Refresh Token used when accessing APIs — is arguably the most concerning issue.
As described in my previous article entitled OIDC, SAML and OAuth 2.0, the likes of OIDC and OAuth 2.0 make use of these tokens as part of each protocol, and when used as intended, provide both Application developers and API developers with great power and flexibility when it comes to customer identity. However, with great power comes great responsibility….
It’s hardly surprising, then, that stealing tokens has become the target for many of the bad actors out there, making XSS still one of the top 3 attacks after more than two decades! For any application, the safe storage of tokens is of paramount importance, but for a SPA — which has a limited set of choices when it comes to secure storage — it’s even more of a challenge. You can read more about token storage and the various options available in my recent article:
With a Single Page Application, the malicious acquisition of an ID Token has the potential for leaking Personally Identifiable Information (PII) — something which could end up being costly from a regulatory compliance perspective, namely GDPR, the CCPA or the like.
With Access Tokens — and more importantly, Refresh Tokens (used extensively if you follow the best practice guidance of “Prefer short-lived tokens”) — then stolen tokens are even more of a concern. Particularly if you also observe the guidance “Follow the Principle of Least Privilege” — which typically means that your SPA will be using more than one Access Token and correspondingly more than one Refresh Token! Stolen OAuth 2.0 tokens mean the potential for far more than just the loss of PII! 😳
A Refresh Token and Access Token invariably come as a pair (which can also include the ID Token, depending on the CIAM implementation being used). Following the Principle of Least Privilege, an application can conceivably end up in possession of multiple token sets, each of which needs to be handled in a safe and secure manner.
Resource Security
Now you may be thinking that following the best practice of “Prefer short-lived tokens” and observing the guidance to “Follow the Principle of Least Privilege” is simply creating unnecessary problems. And, you could be forgiven for thinking that too: just like the claim that “time travel is now simply an engineering problem” is not a statement that either helps or informs physical engineering implementation, neither of the aforementioned addresses the challenges from the perspective of a software engineering standpoint.
However, they do make sense from the perspective of resource security, and one can’t simply ignore them (or at least will do so at their own peril). In a recent post, Andrea Chiarelli — an ex-colleague of mine — neatly describes why both practices are important when it comes to protecting resources:
Taking into consideration one of the key points of a SPA being that page refresh is kept to a minimum, we somehow need to store tokens — and tokens in the plural because there’s likely to be more than one — so that we don’t have to continuously redirect back to the CIAM provider in order to obtain new ones. And that brings us back to the advice, “You’re vulnerable to XSS attacks if you keep tokens in Local Storage!”
If you haven’t already, you can probably now see where I’m coming from when I say it’s a challenge for most software engineering folks to know exactly what to do for the best. And, more importantly, how to do it! When it comes to Customer Identity, a lot of the guidance from subject matter experts can seem tautological and contradictory.
User Experience
There’s also the user experience to consider. Poor UX designs when it comes to Access Control can often leave users frustrated, to say the least. Examples will often show single-shot operations — like clicking a “Delete” button, say — being declined as the API rejects the request due to insufficient privilege at the point at which the user performs the operation. Arguably, that’s OK. However, if I’ve filled in a whole form of data just to be told “sorry, you can’t do that” when I click “Submit”, I’m going to be pretty annoyed 😠
Better Protection via the BFF Pattern
One architectural strategy that has gained prominence to at least improve the security posture of OAuth token handling is the Backend-For-Frontend (BFF) pattern; you can read about it in detail here in the IETF draft entitled OAuth 2.0 for Browser-Based Applications.
As described by Sam Newman in the article here, BFF was a pattern originally designed to make it easier when adapting APIs for use by multiple clients, but in recent years has been somewhat repurposed for Customer Identity. Essentially, this is an architecture pattern in which a server-side component, the BFF, is specifically designed as part of the frontend application and implemented to securely proxy all API calls:
To avoid confusion with other architectural concepts, such as API gateways and reverse proxies, etc., it is important to keep in mind that the BFF pattern is specifically designed as part of the application itself, effectively becoming the OAuth client for the frontend.
SPA (React/Vue/Angular) <---> BFF (Node.js/.NET/etc) <---> OAuth2 Provider- Redirects the user to the CIAM provider.
- Handles the redirect back with authorization code.
- Exchanges the code for access and refresh tokens.
- Stores tokens securely (e.g. Server Memory, Session, or Database).
- Provides authenticated user info to the SPA (e.g., via a
/meendpoint). - Proxies authenticated API requests on behalf of the SPA using the stored Access/Refresh Tokens.
SPA [GET /api/data] <--> BFF [GET /api/data] <--> Protected API [GET /api/data] (using access token)A typical BFF would use HTTP-only, Secure, SameSite cookies for session storage (though can use other mechanisms such as server-side storage), avoiding having to store tokens in localStorage or sessionStorage, both of which are susceptible to XSS.
A BFF is also typically hosted on the same domain as the application/API, and will typically employ a rotational strategy when using Refresh Tokens; a BFF will typically request short-lived Access Tokens and then use a Refresh Token approach to renew them (thus avoiding any redirect to the CIAM provider).
As with any CIAM integration, the use of TLS (HTTPS) would be used everywhere; all of this provides a number of benefits, including:
- Token Isolation: Tokens never reside in the browser-based storage that’s susceptible to an XSS attack.
- Secure Storage: Tokens are stored in secure backend storage or in
HttpOnlycookies. - Centralised Token Management: Token refresh and rotation are handled on the server side
- Session Control: Facilitates tighter control over user sessions, including logout and inactivity management.
In a recent post, Kim Maida, Senior Director of Developer Relations over at FusionAuth, shared details of a demo implementation for Backend-For-Frontend authentication and authorization, and the GitHub repo she mentions is available here. Kim does a really great job of discussing how to build a BFF using both a standards-based approach and also using FusionAuth’s own Hosted Backend technology; a great illustration of how a BFF pattern can be implemented in a way that can avoid any impact of potential vendor lock-in.
I love this kind of “hands-on” approach as it provides explicit, concrete implementation that helps take the guesswork out of the engineering required. However, with my engineering hat on, there are a couple of observations I have when it comes to the BFF approach that aren’t criticisms per se, but predominantly hark back to that frustrating situation where, as an engineer, one is left to work things out for oneself:
- How does the pattern help me when it comes to structuring my UI in a way that reflects what a user is allowed to do?
- How does the pattern help me adhere to the Principle of Least Privilege?
- How do I integrate the BFF pattern whilst still using existing CIAM SDKs?
- How exactly is my BFF being protected? It is an API after all 🤷🏻♂️
- Do I really have to proxy every single call to my own API? 🤔
The ACME Pattern: Revolution Through Evolution
The BFF pattern certainly provides a solution to some of the challenges engineers face, and with the kind of work done by folks like Kim, there’s collateral that can be leveraged to build implementation, meaning we’re not left guessing what we have to do.
But it’s not the whole story; certainly, there are some gaps which I’m left to fill in myself, and for me, it doesn’t solve my requirements when it comes to Access Control (more on that later). Enter the ACME pattern.

Now, ACME isn’t intended to be a replacement for the BFF pattern, or anything else for that matter. In fact, if you are building a BFF for what it was originally intended to provide (i.e. a pattern designed to make it easier when adapting APIs for use by multiple clients), then you can certainly incorporate ACME as part of the design. More than anything, the ACME pattern is designed to complement rather than replace.
ACME — which stands for Access Control Mediation Endpoint — is an architectural pattern that leverages existing concepts from the BFF pattern, the Token-Mediating Backend pattern, and a number of other sources, that essentially collapses more of the Auth responsibility into an API itself.
ACME is a pattern I’m adopting as part of the B2B SaaS solution I’m building (TheatricalPA; for vertical market theatrical production management), and I’ll happily claim the accolade of inventing it…which, in a way, I suppose is true, I have. However, think of it more as an approach that has evolved out of existing patterns like BFF et al, together with concepts borrowed from the likes of OAuth 2.0 itself. Let me elaborate.
Overview
ACME is a pattern I’m going to discuss in more detail in future articles, and I’m even going to be building some code samples that will make it easier to adopt; it shouldn’t just be about what you could engineer, but what you can engineer and also how to engineer it!
For now, though, let me start by providing an overview of how it works. The first part of the process involves the use of the standard Authorization Code Flow (with PKCE, specifically as we’re in a SPA context), as illustrated in the diagram below:
At this point, it’s worth mentioning that, just like the BFF pattern, the ACME Pattern — or to give it its full title, the ACME Pattern for Resource Authorization — isn’t exclusively for use in a SPA. However, it does arguably provide the most benefit in a Single Page Application context, particularly from the perspective of token protection.
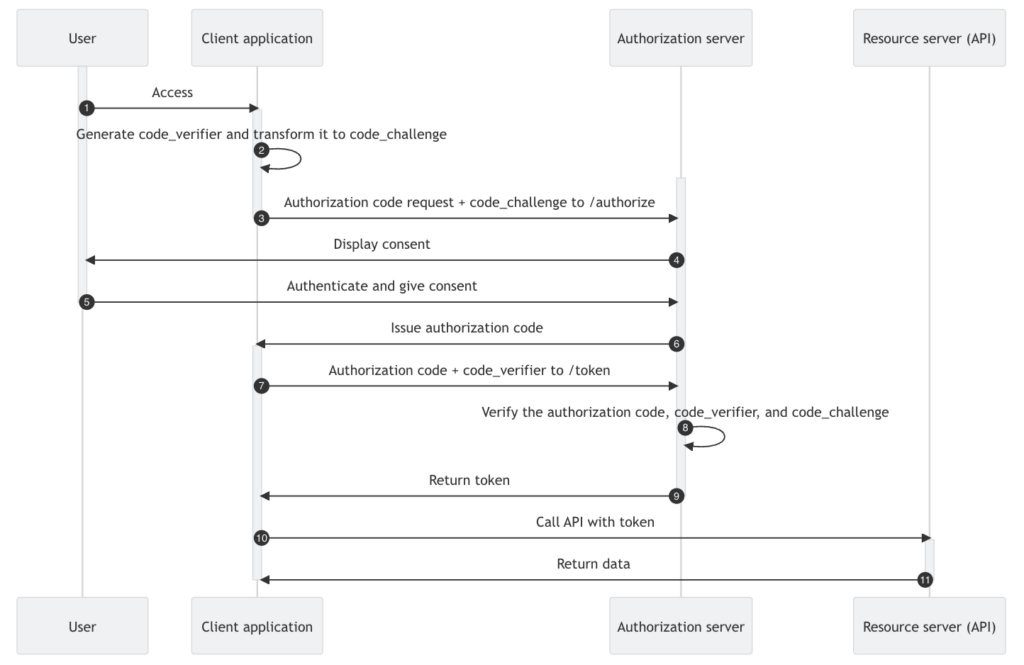
- This is a well-known process that, in particular, will establish the identity of the user and will also establish an SSO session with the CIAM provider. Additionally, this is the standard out-of-box process that is typically performed by most third-party CIAM provider SPA SDKs (such as keycloak.js, @react-keycloak/web, auth0-spa-js, @auth0/auth0-react, @fusionauth/react-sdk, etc).
- As part of the standard out-of-box process, we’re going to be requesting an Access Token with a single scope that we’ll refer to as
endpoint:mediate(the name is immaterial, but using the convention of resource:action, this seems a fitting choice given the part it will play). Depending on the CIAM provider you’re integrating with, this will likely be defined as a custom scope, and the use of a customaudiencemay also be required.
- An SDK will typically establish an application session context using the returned ID Token, and the process of doing so should follow best practice guidance. Arguably, it isn’t always the case that best practice guidance is observed by the SDK vendor, and there’ve been some interesting differences of opinion regarding this in recent times (see the thread here for an example).
- If you are in doubt as to whether the SDK offered by your CIAM provider gives you the best protection, there is an alternative you can adopt using the ACME pattern. It largely borrows from the aforementioned BFF pattern
/meendpoint functionality, and I’ll be discussing it in a future article.
- If you are in doubt as to whether the SDK offered by your CIAM provider gives you the best protection, there is an alternative you can adopt using the ACME pattern. It largely borrows from the aforementioned BFF pattern
- The Access Token returned will be used to call your API (step 10 onwards in the diagram above). Now, the eagle-eyed amongst you may already be thinking “….hang on, but I’ve not specified the scope(s) I need in order to make the Access Token usable by my API 🤔…” That’s correct. What we have at the moment is an Access Token that will be used to facilitate API calls, but it doesn’t actually “carry” the security that the resource server will typically require. This makes the Access Token fairly inert from a security perspective, so it’s relatively innocuous, which, in turn, makes the storage of it relatively straightforward.
- Most third-party provider SDKs — e.g. @react-keycloak/web — will likely store the Access Token in memory, but localStorage or even sessionStorage should be OK too. As the token is not directly valuable from a resource perspective, should it be leaked through something like an XSS attack, a bad actor cannot successfully use it to directly access resources.
- For each “page” rendered by the application, a
GETAPI call will first be made to an/authorizeendpoint associated with the accompanying API route hierarchy (or hierarchies if there’s more than one). This endpoint is what I refer to as the API Route Authority (or Route Authority for short), and again, the name of the endpoint is fairly immaterial. I’ve used/authorizebecause it makes sense in the context of what the endpoint actually does. For example, in the B2B SaaS I’m building, I have the notion of a Production and various aspects associated with it, so I have the corresponding associations:- Route(s) in my application that refer to discrete Production functionality — for example, the page which surfaces the UX for assembling a team of production participants — and as such, I include a call executed as part of the page’s
useEffectthat makes the initialGETto the corresponding API route authority. - An API route hierarchy associated with Production functionality, as, essentially, a collection of API routes and sub-routes:
/production/authorize– the production route authority/production/id– to manage a specific production with theididentifier/production/id/team– to manage a team associated with productionid/production/id/schedule– to manage a schedule associated with productionid- etc.
- Route(s) in my application that refer to discrete Production functionality — for example, the page which surfaces the UX for assembling a team of production participants — and as such, I include a call executed as part of the page’s
Route Authority
Now, you may already be asking yourself why there is potentially more than one /authorize endpoint implemented as part of the ACME pattern? As I say, each /authorize endpoint — each Route Authority — is associated with an API route hierarchy, making it possible to define discrete areas of discrete functionality and thus satisfy the “Principle of Least Privilege” recommended best practice: the Access Token used for Production functionality doesn’t need to carry the scopes required for Publicity or Rehearsal management, say, and vice versa.
Implementing Route Authority also makes you consider the nature of your API and helps focus the development of endpoints in a way that makes logical sense.
The Route Authority also kind of echoes the /authorize endpoint provided by the authorization server (as illustrated in the above diagram and as described in the OAuth 2.0 spec), save for the following fundamental differences:
- Your API will typically surface more than one
/authorizeendpoint (though not specifically required), - The only supported parameters are
scopeandredirectUri, and - Each instance is multi-functional:
- Via an HTTP redirect, mediation can be triggered, which can perform what I’ll refer to as Bearer Token elevation; more on that later.
- Via an HTTP
GET, that includes a Bearer Token possessing theendpoint:mediatescope, a list of available/required permissions can be obtained.- A
GETAPI call to an/authorizeendpoint, with a suppliedscopeparameter, can return a list of permissions which can be used to inform the UX as described in the Access Control Enablement section below. - A
GETAPI call to an/authorizeendpoint, with a suppliedscopeparameter, can return HTTP401(Unauthorised), meaning the user represented by the Bearer Token does not have the desired access. - A
GETAPI call to an/authorizeendpoint, with a suppliedscopeparameter, can return HTTP401(Unauthorised) with a specific reason code. The reason code can essentially be anything, but again, using accepted convention based on its use, let’s go with"Mediation Advised"
- A
Mediation Advisory
For now, let’s focus on the latter. On receipt of an HTTP 401 with reason code "Mediation Advised", the application (i.e. the SPA in this case) would redirect to the same route authority (/authorize) endpoint. To start with, the redirect is essentially going to trigger first-factor authentication, via whatever CIAM solution is employed; this should effectively be “silent” due to the SSO session already established.
Actually, if the SSO session has terminated, then interactive first-factor authentication will be triggered, which automatically handles the case where a user needs to re-enter their credentials because of session expiry. In fact, in a similar fashion, this also automatically handles the case where step-up authentication is required, too.
The redirect is also going to return an Access Token containing the necessary scopes, together with a corresponding Refresh Token. This shares similarities with the Token-Mediating Backend pattern except that (as with the BFF pattern) neither the Access Token nor the Refresh Token is returned to the client application.
Instead, the route authority associates both tokens with the API route it services. There are various ways to do this, but the simplest and most effective way is, by default, to create an HttpOnly cookie — or, rather, two cookies, one for each token — setting the Path for each to the base of the route hierarchy.
Section 5.1.4 of RFC 6265 (HTTP State Management Mechanism) describes Cookie Path and path matching, and how a subordinate path (route) can access a cookie and under what circumstances.
Now the API route authority can essentially use any secure storage mechanism, but cookies — specifically HTTPOnly cookies — are really useful as, for a SPA, the browser will typically take care of things like cookie transport and cookie cleanup without further intervention by an API or application. There are some specific considerations regarding these cookies, and I’ll go into more details regarding these in the future; suffice it to say that each cookie will use the HttpOnly, Secure, Path and SameSite attributes.
Finally, the API authority will redirect via the supplied redirectUri to the application. For simplicity’s sake, I haven’t implemented CORS as both my first-party application and my first-party API are surfaced on the same domain. However, there isn’t anything to stop Cross-Origin Resource Sharing from being implemented, and this is probably something I’ll discuss more in a future article.
Execution continues, and with control now handed back to the application — i.e. the SPA in this case — page load again causes the GET API call to be made to the /authorize endpoint associated with the accompanying API route hierarchy. This time, it returns the list of available permissions for the user. The UX can be rendered accordingly, and calls to the API can be made as the user interacts with the UI.
Bearer Token Elevation
So what about API calls? Well, remember, at this point, the application holds the one and only innocuous Access Token with endpoint:mediate scope, so that gets used as part of each API call (set as an Authorization Bearer header in the usual way). Nothing out of the ordinary so far. The novelty comes in how each API endpoint is implemented to handle the bearer token supplied.
Unlike with the BFF pattern, ACME is designed so that the API participates directly without the need for any additional overhead introduced by using a BFF proxy.
If an API endpoint receives a Bearer Token with the appropriate scope(s), then it operates in accordance with the standard best practices associated with the OAuth 2 protocol. If the Bearer Token an API endpoint receives does not contain the appropriate scope(s), but does have the endpoint:mediate scope, then a sequence is performed (ideally via some implemented middleware) in what I like to call Bearer Token Elevation:
- The API will attempt to locate the corresponding (elevated) token generated as part of the advised mediation discussed above. If you’re using
HttpOnlycookie storage, then the API will attempt to retrieve/use the Access Token from the appropriate cookie, using the token received in theAuthorization Bearerheader as a guide. - If no Access Token is found, or the Access Token has expired, but there is a corresponding Refresh Token, then the API will attempt to generate a new Access Token via a call to the integrated CIAM provider, and use that.
- If the Refresh Token has been revoked, then the API will return with a
401and typically with"Mediation Advised"as the reason code.
- If the Refresh Token has been revoked, then the API will return with a
- With the elevated token, if the user cannot perform the requisite action due to a lack of permission, then a standard
401will be returned. - With the elevated token, if the user can perform the action then the API will execute as normal.
By incorporating the use of standard Authorization Bearer header workflow with token elevation, the API can be securely accessed and presented with enough information to also securely enable the additional (elevation) processing. It also means that if your CIAM provider supports the likes of Token Binding (RFC 8471 / RFC 8473), then you can extend an ACME implementation to make use of that too; particularly useful if you also want to support CORS (directly) from your API.
Whilst the specification for OAuth 2.0 (RFC 6749) describes Bearer Token usage (RFC 6750), neither spec mandates that the Bearer Token ultimately used by a resource server must be directly obtained from an HTTP Authorization Bearer header.
Access Control Enablement
Aside from how easy it lets you observe the recommended best practices advised by CIAM specialists — particularly when building a SPA — the enhanced security it automatically provides, and the reduction in overhead compared to implementing the BFF pattern, the ACME pattern facilitates access control enablement in a way that is easy to implement and easy to manage across all first-party applications using your API.
Adopting the ACME pattern also opens the door to integrating the fine-grained access control mechanisms provided by the likes of OpenFGA, Permit.io, et al, all with minimal additional impact to application or API design. I’ll be sharing more on that in future articles.
Ultimate Protection
Ultimate may be a strong word, but with ACME, we satisfy the best practice recommendations, which typically state: “You’re vulnerable to XSS attacks if you keep tokens in Local Storage!”, “Prefer short-lived tokens”, “Use a BFF“, and “Follow the Principle of Least Privilege“.
Whilst not a BFF exactly, ACME does serve as a secure intermediary, particularly for Single Page Applications, and unlike a BFF, it doesn’t require the overhead of proxying every API call. Further, ACME opens the door to integrating the fine-grained access control mechanisms with minimal additional impact on application or API design. I’m even starting to think about how ACME can help with AI implementations, particularly when it comes to the likes of MCP integration.
So, perhaps “ultimate” isn’t such a strong word after all 😉 Anyway, I hope you’ve enjoyed this article, and please feel free to reach out with your thoughts and let me know what you think. Bye for now 😎



















Leave a Reply